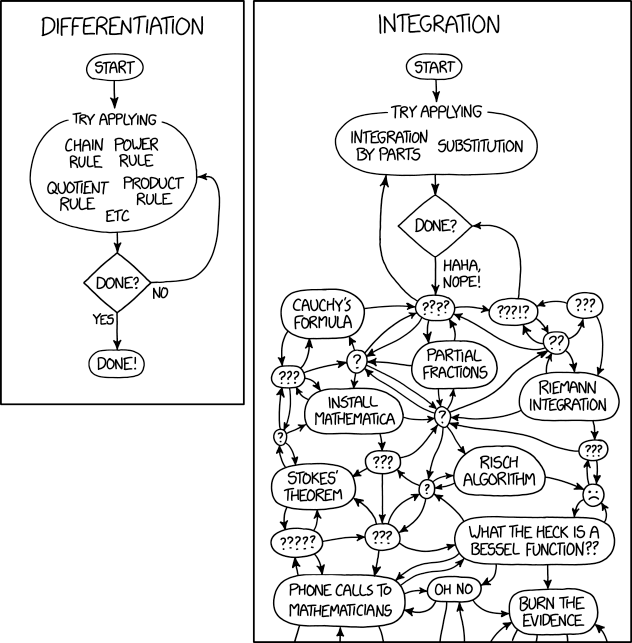
Recently, I posted a link to the above XKCD cartoon to social media and was asked if I could provide an explanation of why differentiation is relatively easy while integration is quite hard in comparison.
Differentiation: Let's begin by laying out the ground rules. We're interested in finding a formula for the derivative of a function given as a symbolic expression rather than computing a numerical approximation to the derivative of some function computed numerically (the latter problem is actually much harder in practice.) We'll assume that our expression is written in terms of elementary operations: addition, subtraction, multiplication, division, powers (including roots), exponentials, logs, trig functions (sin, cos, tan, and their inverses.) We'll call a function \( f(x) \) elementary if it can be expressed in this way.
In your first semester of freshmen calculus, you learned a set of rules for computing derivatives that included rules for the derivatives of sums, products, and quotients of functions as well as trig functions, powers, exponentials, and logs. Most importantly, you learned the chain rule for the derivative of the composition of two functions:
\( (f(g(x))'=f'(g(x))g'(x). \)
By applying these rules of differentiation recursively, you can systematically find the derivative of any elementary function. Implementing symbolic differentiation in a functional programming language like Lisp makes for a nice homework exercise.
It's important to understand that these rules produce expressions that themselves are made up entirely of elementary functions. Thus we say that the set of elementary functions is closed under differentiation.
Note that although the set of functions that can be produced by differentiation of elementary functions is contained in the set of elementary functions, it doesn't consist of all elementary functions- there are elementary functions that can't be reached by starting with an elementary function and differentiating it.
Integration: Now suppose that we're given an expression written in terms of elementary functions and want to reverse the process to find its indefinite integral (also called the antiderivative.) Definite integrals over an interval are also of interest, but they can be evaluated by using the antiderivative.
In second semester calculus, we teach students techniques of integration, which are basically heuristic procedures for reverse the process of differentiation step by step. For example, the substitution method is simply a process for applying the chain rule:
\( \int f'(u(x)) u'(x) dx = f(u(x))+C \)
where \( C \) is an arbitrary constant (whose derivative is 0.)
One difficulty in this approach to integration is that it isn't always clear which technique of integration should be applied. Furthermore, it may be necessary to apply several of the techniques in order to fully evaluate the integral.
A more significant problem is that it is possible to write down an elementary function that is not the derivative of any elementary function. Therefore, the indefinite integral of such a function can't be written in terms of elementary functions. A famous example of this is
\( \int e^{-x^{2}} dx \).
A theorem due to Liouville gives conditions that determine whether or not an elementary function has an elementary antiderivative (Liouville had several theorems named after him- this is the one in differential algebra.) Liouville's theorem is nontrivial to explain and in practice, it isn't possible to check the conditions by hand for most integrals. Risch's algorithm is a systematic procedure that can distinguish between these cases and produce the integral when it is an elementary function.
Symbolic computation packages such as Maple and Mathematica used to evaluate integrals by the same kinds of heuristic techniques of integration that we teach to students in Calculus II. More recently, these packages have incorporated more or less complete implementations of the Risch algorithm. However, the algorithm is extremely difficult to fully implement and these packages can still fail to evaluate many integrals. This is an area where human expertise is still quite valuable.
Users often want to see and understand the steps taken in evaluating an integral, but it's impractical to follow the steps of the Risch algorithm, so software packages offer evaluation by conventional techniques of integration with step by step descriptions.
Special Functions: Beyond elementary functions, there are also so-called "special functions" that are defined in terms of integrals or solutions of differential equations that cannot be expressed in terms of elementary functions. For example, the complementary error function is defined as:
\( \mbox{erfc}(z)=\frac{2}{\sqrt{\pi}} \int_{z}^{\infty} e^{-x^{2}} dx \).
This function is useful in the statistical analysis of measurement errors. We've already mentioned that \( e^{-x^{2}} \) is an example of a function that can't be integrated in terms of elementary functions. However, there are many numerical methods for approximating this complementary error function and it is useful enough that it is commonly implemented in libraries of special functions.
Further Reading
Bronstein, Manuel. “Integration of Elementary Functions.” Journal of Symbolic Computation 9, no. 2 (February 1, 1990): 117–73. https://doi.org/10.1016/S0747-7171(08)80027-2.
Churchill, R. C. “Liouville’s Theorem on Integration in Terms of Elementary Functions.” In Lecture Notes for the Kolchin Seminar on Differential Algebra, 2002. https://ksda.ccny.cuny.edu/PostedPapers/liouv06.pdf.
Conrad, Brian. “Impossibility Theorems for Elementary Integration.” In Academy Colloquium Series. Clay Mathematics Institute, Cambridge, MA. Citeseer, 2005. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.482.3491&rep=rep1&type=pdf.
Cruz-Sampedro, Jaime, and Margarita Tetlalmatzi-Montiel. “Hardy’s Reduction for a Class of Liouville Integrals of Elementary Functions.” The American Mathematical Monthly 123, no. 5 (May 1, 2016): 448–70. https://doi.org/10.4169/amer.math.monthly.123.5.448.
Fitt, A. D., and G. T. Q. Hoare. “The Closed-Form Integration of Arbitrary Functions.” The Mathematical Gazette 77, no. 479 (July 1993): 227. https://doi.org/10.2307/3619719.
Geddes, K. O., S. R. Czapor, and G. Labahn. “The Risch Integration Algorithm.” In Algorithms for Computer Algebra, edited by K. O. Geddes, S. R. Czapor, and G. Labahn, 511–73. Boston, MA: Springer US, 1992. https://doi.org/10.1007/978-0-585-33247-5_12.
Kasper, Toni. “Integration in Finite Terms: The Liouville Theory.” SIGSAM Bull. 14, no. 4 (November 1980): 2–8. https://doi.org/10.1145/1089235.1089236.
Marchisotto, Elena Anne, and Gholam-Ali Zakeri. “An Invitation to Integration in Finite Terms.” The College Mathematics Journal 25, no. 4 (September 1994): 295. https://doi.org/10.2307/2687614.
Moses, Joel. “An Introduction to the Risch Integration Algorithm.” In Proceedings of the 1976 Annual Conference, 425–428. ACM ’76. New York, NY, USA: ACM, 1976. https://doi.org/10.1145/800191.805632.
Risch, Robert H. “The Problem of Integration in Finite Terms.” Transactions of the American Mathematical Society 139 (May 1969): 167. https://doi.org/10.2307/1995313.
Risch, Robert H. “The Solution of the Problem of Integration in Finite Terms.” Bulletin of the American Mathematical Society 76, no. 3 (May 1970): 605–8.
Ritt, Joseph Fels. Integration in Finite Terms: Liouville’s Theory of Elementary Methods. 1st edition. Columbia Univ. Press, 1948.
Rosenlicht, Maxwell. “Integration in Finite Terms.” American Mathematical Monthly, 1972, 963–972.
Rosenlicht, Maxwell. “Liouville’s Theorem on Functions with Elementary Integrals.” Pacific Journal of Mathematics 24, no. 1 (January 1, 1968): 153–61. https://doi.org/10.2140/pjm.1968.24.153.
Trager, Barry Marshall. “Integration of Algebraic Functions.” Massachusetts Institute of Technology, 1984. http://dspace.mit.edu/handle/1721.1/15391.




{kind=link}